Concepts généraux de Sarracenia
Le présent document décrit idées fondamentales à Sarracénia. Il n’est pas clair dans quelle mesure ces informations sont directement applicables à une utilisation normale, mais il semble que cette information devrait être disponible en quelque part.
Introduction
Les pompes Sarracenia forment un réseau. Le réseau utilise des courtiers ( broker ) amqp pour modéré les transferts de fichiers entre les pompes. On envoie les avis de nouveau fichiers dans un sens et les rapports de succès ou trouble dans la direction opposée. Les administrateurs configurent les chemins d’accès à travers lesquels les données circulent. Chaque pompe agit de façon indépendante, en gérant les activités des moteurs de transfert qu’il peut atteindre, sans connaissance de l’ensemble du réseau. Les emplacements de pompes et les directions du flux de circulation sont choisis pour travailler avec les débits autorisés. Idéalement, aucune exception de règle de pare-feu et nécessaire.
Sarracenia ne transporte pas de données. Il s’agit d’une couche de gestion pour coordonner les activités de l’utilisation d´engins de transport. Donc, pour obtenir une pompe fonctionnelle, les mécanismes de transport réels doivent également être mis en place. Les deux mécanismes actuelles sont le web et SFTP. Dans le cas le plus simple, tous les composants se trouvent sur le site Web du même serveur, mais cela n’est pas nécessaire. Le courtier pourrait être sur un serveur différent de l´origine et la destination d’un transfert.
La meilleure façon d’effectuer des transferts de données est d’éviter les sondages (examination récurrente de répertoires afin de détecter des changements de fichiers.) C’est plus efficace si les rédacteurs peuvent être amenés à émettre des messages sr_post (avis) appropriés. De même, lors de la livraison, il est idéal si les destinataires utilisent sr_subscribe, et un plugin on_file pour déclencher leur traitement ultérieur, de sorte que le fichier est qui leur a été remis sans sondage. C’est la façon la plus efficace de travailler, mais… il est entendu que pas tous les logiciels ne seront coopératifs. Pour démarrer le flot en Sarracenia dans ces cas, ca prend des outils de sondage: sr_poll (à distance), et sr_watch (locale.)
D’une manière générale, Linux est la principale cible de déploiement et la seule plate-forme sur laquelle les configurations de serveur sont déployées. D’autres plates-formes sont utilisées en configuration client. Ceci n´est pas une limitation, c’est juste ce qui est utilisé et testé. Implémentations de la pompe sur Windows devrait fonctionner, ils ne sont tout simplement pas testés.
Corréspondance des concepts AMQP avec Sarracenia
Une chose que l’on peut dire sans risque est qu’il faut comprendre un peu l’AMQP pour travailler avec Sarracenia. L’AMQP est un sujet vaste et intéressant en soi. On ne tente pas de toute expliquer ici. Cette section fournit juste un peu de contexte, et introduit seulement les concepts de base nécessaires à la compréhension et/ou à l’utilisation de la Sarracenia. Pour plus d’informations sur l’AMQP lui-même, un ensemble de liens est maintenu à l’adresse suivante le site web Metpx mais un moteur de recherche révèlera aussi une richesse matérielle.

Un serveur AMQP s’appelle un courtier. Le mot Courtier est parfois utilisé pour faire référence au logiciel, d’autres fois serveur exécutant le logiciel de courtage (même confusion que serveur web). ci-dessus, le vocabulaire de l’AMQP est en orange, et les termes de Sarracenia sont en bleu. Il y a de nombreuses et différentes implémentations de logiciels de courtage. Nous utilisons rabbitmq. Nous n’essayons pas d´être spécifique au rabbitmq, mais les fonctions de gestion diffèrent d’une implémentation à l’autre.
- Les Queues (files d´attentes) sont généralement prises en charge de manière transparente, mais vous avez besoin de connaître
-
- Un consommateur/abonné crée une file d’attente pour recevoir des messages.
- Les files d’attente des consommateurs sont liées aux échanges (langage AMQP).
Un exchange est un entremeteur entre publisher et les files d´attentes du consumer
- Un message arrive d’une source de données.
- l´avis passe à travers l’échange, est-ce que quelqu’un est intéressé par ce message ?
- dans un échange basé sur un topic, le thème du message fournit la clé d’échange.
- intéressé : comparer la clé de message aux liaison des queues de consommateurs.
- le message est acheminé vers les files d’attente des consommateurs intéressés, ou supprimé s’il n’y en a pas.
- Plusieurs processus peuvent partager une files d’attente, ils enlèvent les messages à tour de rôle.
-
- Ceci est fortement utilisé pour sr_sarra et sr_subcribe multiples instances.
- Queues* peut être durable, donc même si votre processus d’abonnement meurt,
-
- si vous revenez dans un délai raisonnable et que vous utilisez la même file d’attente,
- vous n’aurez manqué aucun message.
- Comment décider si quelqu’un est intéressé.
-
- Pour la Sarracenia, nous utilisons (standard AMQP) échanges thématiques.
- Les abonnés indiquent les thèmes qui les intéressent et le filtrage se fait côté serveur/courtier.
- Les thèmes sont juste des mots-clés séparés par un point. wildcards : # correspond à n’importe quoi, * correspond à un mot.
- Nous créons la hiérarchie des thèmes à partir du nom du chemin d’accès (mappage à la syntaxe AMQP).
- La résolution et la syntaxe du filtrage des serveurs sont définies par l’AMQP. (. séparateur, # et * caractères génériques)
- Le filtrage côté serveur est grossier, les messages peuvent être filtrés après le téléchargement en utilisant regexp
- topic_prefix ? Nous commençons l’arborescence des sujets avec des champs fixes.
-
- v02 la version/format des messages de Sarracenia.
- post …. le type de message, il s’agit d’une annonce d’un fichier (ou d’une partie d’un fichier) disponible.
Sarracenia est une application AMQP
MetPX-Sarracenia n’est qu’un léger enrobage autour de l’AMQP.
- Une pompe de données MetPX-Sarracenia est une application python AMQP qui utilise un (rabbitmq). pour coordonner les transferts de données des clients SFTP et HTTP, et accompagne un serveur web (apache) et serveur sftp (openssh), souvent sur la même adresse en face de l’utilisateur.
- Dans la mesure du possible, nous utilisons leur terminologie et leur
syntaxe. Si quelqu’un connaît l’AMQP, il comprend. Si ce n’est pas
le cas, ils peuvent faire des recherches.
- Les utilisateurs configurent un courtier, au lieu d’une pompe.
- par convention, le serveur virtuel par défaut’/’ est toujours utilisé. (n’a pas encore ressenti le besoin d’utiliser d’autres serveurs virtuels)
- les utilisateurs peuvent explicitement choisir leurs noms files d’attente.
- les utilisateurs définissent subtopic,
- les sujets avec séparateur de points sont transformés au minimum, plutôt qu’encodés.
- file d’attente durable.
- nous utilisons des en-têtes de message (langage AMQP pour les paires clé-valeur) plutôt que d’encoder en JSON ou dans un autre format de charge utile.
-
- réduire la complexité par le biais de conventions.
-
- n’utiliser qu’un seul type d’échanges (Topic), prendre soin des fixations.
-
- conventions de nommage pour les échanges et les files d’attente.
-
- les échanges commencent par x.
- xs_Weather - l’échange pour la source (utilisateur amqp) nommé Weather pour poster des messages.
- xpublic – central utilisé pour la plupart des abonnés.
- les files d’attente commencent par q
- les échanges commencent par x.
Le flot à travers des Pompes
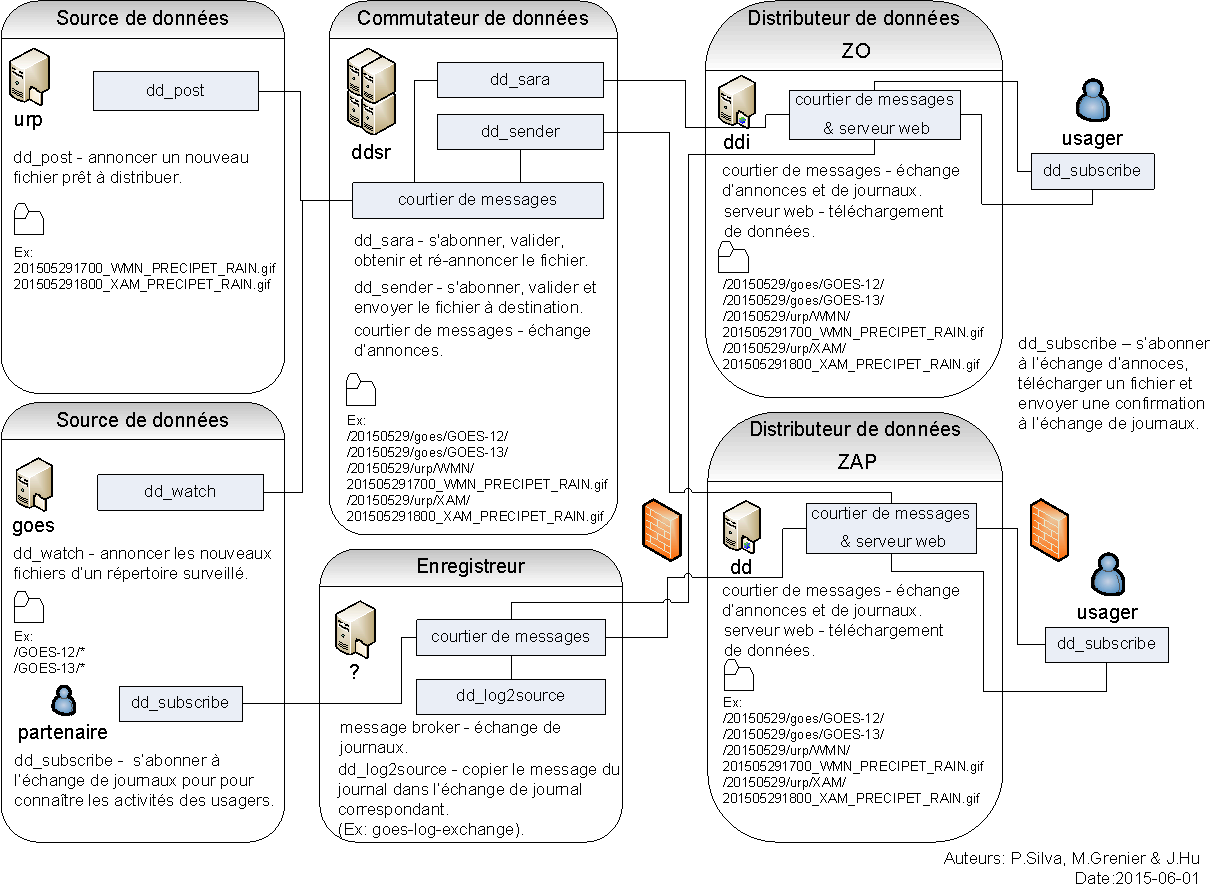
Une description du flux conventionnel de messages par le biais d’échanges sur une pompe :
- Les abonnés se lient généralement à l’échange public pour obtenir le flux de données principal. c’est la valeur par défaut dans sr_subscribe.
- Un utilisateur nommé Alice aura deux échanges :
- xs_Alice l’échange où Alice poste ses notifications de fichiers et ses messages de rapports.(via de nombreux outils)
- xr_Alice l’échange où Alice lit ses messages de rapport (via sr_report).
- généralement sr_sarra lira à partir de xs_alice, récupérer les données correspondant à Alice´s post et le rendre disponible sur la pompe, en l’annonçant à nouveau sur le réseau public.
- sr_winnow peut tirer de xs_alice à la place, mais suit le même modèle que sr_sarra.
- habituellement, sr_audit –users causera des configurations de pelles rr_alice2xreport de rr_alice2xreport pour lire xs_alice et copier les messages de rapport sur l’échange privé xreport.
- Les administrateurs peuvent pointer sr_report à l’échange xreport pour obtenir une surveillance à l’échelle du système. Alice n’aura pas la permission de faire ça, elle ne peut que regarder xl_Alice, qui aurait dû avoir les messages du rapport qui la concernent.
- – rr_xreport2source shovel configurations auto-générées par sr_audit look
-
at messages for the utilisateur Alice local dans xreport, et les envoie à xl_Alice.
L’objectif de ces conventions est d’encourager un mode de fonctionnement raisonnablement sûr. Si un message est tiré de xs_Alice, alors le processus de lecture est responsable de ce qui suit en s’assurant qu’il est étiqueté comme venant d’Alice sur ce cluster. Cela permet d’éviter certaines types de ´spoofing´ comme les messages ne peuvent être affichés que par les propriétaires appropriés.
Utilisateurs et rôles
Les noms d’utilisateur pour l’authentification des pompes sont significatifs dans la mesure où ils sont visibles par tous. Ils sont utilisés dans le chemin du répertoire sur les arbres publics, ainsi que pour authentifier le courtier. Ils doivent être compréhensibles. Ils ont souvent une portée plus large qu’une personne, peut-être les appeler “Comptes”. Il peut être élégant de configurer les mêmes noms d’utilisateur pour une utilisation dans les moteurs de transport.
Tous les noms de compte doivent être uniques, mais rien n’évitera les conflits lorsque les sources proviennent de différents réseaux de pompes, et des clients à différentes destinations. Dans la pratique, les conflits de noms sont les suivants adressée par routage pour éviter que deux sources différentes’ avec le même nom aient leur nom. les offres de données combinées sur un seul arbre. D’autre part, les conflits de noms ne sont pas toujours une erreur. L’utilisation d’un nom de compte source commun sur différents clusters peut être utilisée pour implémenter des dossiers qui sont partagés entre les deux comptes portant le même nom.
Les utilisateurs de pompe sont définis avec l’option declare. Chaque option commence avec l’option declare suivi du rôle spécifié, et enfin le nom de l’utilisateur qui a ce rôle. rôle peut en être un de :
- subscriber
-
Un subscriber ( abonné ) est un utilisateur qui ne peut s’abonner qu’aux messages de données et de rapport. Interdiction d’injecter des données. Chaque abonné reçoit un xs<user> named exchange sur la pompe, où si un utilisateur est nommé Acme, l’échange correspondant sera xs_Acme. Cet échange est l’endroit où un sr_subscribe sr_subscribe enverra ses messages de rapport.
Par convention/défaut, l’utilisateur anonyme est créé sur toutes les pompes pour permettre l’abonnement sans un compte spécifique.
- source
-
Un utilisateur autorisé à s’abonner ou à générer des données. Une source ne représente pas nécessairement une personne ou un type de données, mais plutôt une organisation responsable des données produites. Ainsi, si une organisation recueille et met à disposition dix types de données avec un seul interlocuteur email ou numéro de téléphone pour des questions sur les données et leur disponibilité, alors tous les ces activités de recouvrement pourraient utiliser un seul compte “ source ”.
Chaque source a un échange xs<user> pour l’injection de messages de données, et, similaire à un abonné, pour envoyer des messages de rapport sur le traitement et la réception des données.
Chaque source est en mesure de visualiser tous les messages pour les données qu’elle a injectées, mais l’endroit où tous ces messages sont disponibles varie en fonction de la configuration de l’administrateur du routage des rapports. Ainsi, une source peut injecter des données sur la pompe A, mais peut s’abonner à des rapports sur une pompe différente. Les rapports correspondant aux données que la source injectée est écrite en échange xl<user>.
Lors de l´injection initiale des données, le chemin est modifié par Sarracenia pour préparer une partie supérieure fixe de l’arborescence des répertoires. Le premier niveau d’annuaire est le jour de l’ingestion dans le réseau en format AAAAMMJJJ. Le répertoire de deuxième niveau est le nom de la source. Donc pour une utilisatrice Alice, s’injecter le 4 mai 2016, la racine de l’arborescence du répertoire est : 20160504/Alice. Notez que tous les on s’attend à ce que les pompes fonctionnent dans le fuseau horaire UTC.
Il y a des annuaires quotidiens parce qu’il y a une durée de vie à l’échelle du système pour les données, elle est supprimée.
Puisque tous les clients verront les répertoires, et donc les configurations des clients les incluront. il serait sage de considérer le nom du compte public, et relativement statique.
Les sources déterminent qui peut accéder à leurs données, en spécifiant à quelle grappe envoyer les données.
- feeder
-
un utilisateur autorisé à s’abonner ou à générer des données, mais considéré comme représentant une pompe. Cet utilisateur local de pompe serait utilisé pour exécuter des processus tels que sarra, le routage des rapports report avec des shovels, etc….
- administration
-
un utilisateur autorisé à gérer la pompe locale. C’est le véritable administrateur rabbitmq-server. L’administrateur exécute sr_audit pour créer/supprimer. les échanges, les utilisateurs, les files d’attente non utilisées, etc…. etc.
Exemple d’un fichier admin.conf valide complet, pour un hôte nommé blacklab :
cluster blacklab
admin amqps://hbic@blacklab/
feeder amqps://feeder@blacklab/
declare source goldenlab
declare subscriber anonymous
Un credentials.conf correspondant ressemblerait à:
amqps://hbic:hbicpw@blacklab/
amqps://feeder:feederpw@blacklab/
amqps://goldenlab:puppypw@blacklab/
amqps://anonymous:anonymous@blacklab/
Engins de transport
Les engins de transport sont les serveurs de données interrogés par les abonnés, par les utilisateurs finaux ou d’autres pompes. Les abonnés lisent les avis et récupèrent les données correspondantes, en utilisant le protocole indiqué. Le logiciel pour servir les données peut être SFTP ou HTTP (ou HTTPS). En configurant les serveurs pour l’utilisation, veuillez consulter la documentation des serveurs eux-mêmes. Notez également que les protocoles additionnels peuvent être activés par l’utilisation des plugins do_ plugins, tels que décrit dans le Guide de programmation.
IPv6
Une pompe d’échantillonnage a été implémentée sur un petit VPS avec IPv6 activé. Un client lointain connecté au courtier rabbitmq en utilisant IPv6, et l’abonnement au httpd apache httpd a travaillé sans problèmes. It just works. Il n’y a pas de différence entre IPv4 et IPv6. Sarracenia est agnostiques aux adresses IP.
On s’attend à utiliser des noms d’hôtes, puisque l’utilisation d’adresses IP brisera le certificat. Utilisation pour la sécurisation de la couche de transport (TLS, aka SSL) Pas de test des adresses IP dans les URLs (dans l’une ou l’autre IP)) a été réalisée.
Plans de Pompes
Il existe de nombreux arrangements différents dans lesquels la Sarracenia peut être utilisée.
- Dataless
-
où l’on ne fait que de la Sarracenia en plus d’un courtier sans moteur de transfert local. Ceci est utilisé, par exemple pour exécuter sr_winnow sur un site pour fournir des sources de données redondantes.
- Autonome
-
la plus évidente, exécuter toute la pile sur un seul serveur, openssh et un serveur web ainsi que le courtier et Sarra lui-même. Réalise une pompe de données complète, mais sans redondance.
- Commutateurs/Routage
-
Où, afin d’atteindre des performances élevées, un cluster de nœuds autonomes sont placés derrière les nœuds suivants un équilibreur de charge. L’algorithme de l’équilibreur de charge n’est que round-robin, sans tentative d’association d´une source donnée avec un noeud donné. Ceci a pour effet de pomper différentes parties de fichiers volumineux à travers différents nœuds. Ainsi on verra des parties de fichiers annoncés par une telle pompe, à être réassemblés par les abonnés.
- Diffusion des données
-
Lorsque, afin de servir un grand nombre de clients, plusieurs serveurs identiques, chacun d’entre eux ayant un système d’exploitation complet, miroitent des données
- FIXME :
-
Ok, j’ai ouvert la grande gueule, il faut maintenant travailler sur les exemples.
Dataless ou S=0
Une configuration qui n’inclut que le courtier AMQP. Cette configuration peut être utilisée lorsque les utilisateurs ont accès à de l’espace disque aux deux extrémités et n’ont besoin que d’un médiateur. Voici la configuration de hpfx.science.gc.ca, où l’espace disque HPC fournit l’espace de stockage de sorte que la pompe ne pas besoin de pompes ou de pompes déployées pour fournir une HA redondante aux centres de données distants.
… note:
FIXME : exemple de configuration des pelles, et sr_winnow (avec sortie
vers xpublic) pour permettre dans le CPS pour obtenir des données de edm
ou dor.
Notez que si une configuration peut être sans données, elle peut toujours utiliser rabbitmq clustering pour les besoins de haute disponibilité (voir ci-dessous).
Dataless vannée
Un autre exemple de pompe sans données serait de fournir une sélection de produits à partir de deux pompes en amont en utilisant sr_winnow. Le sr_winnow est alimenté par des pelles provenant de sources en amont. les clients locaux se connectent simplement à cette pompe locale. sr_winnow prend le soin de ne présenter que les produits du premier serveur à les rendres disponibles. On configurerait sr_winnow pour la sortie vers l’échange xpublic sur la pompe.
Les abonnés locaux ne font que pointer vers la sortie de sr_winnow sur la pompe locale. Ce est la manière dont les aliments sont mis en œuvre dans les centres de prévision des intempéries de ECCC, où ils peut télécharger des données à partir de n’importe quel centre national qui produit les données en premier.
Dataless Avec Sr_poll
Le programme sr_poll peut sonder (vérifier si les produits sur un serveur distant sont prêts ou modifiés.) Pour chaque produit, il émet une avis sur la pompe locale. On pourrait utiliser sr_subscribe n’importe où, écoutez les annonces et obtenez les produits (à condition que l’option avoir les informations d’identification pour y accéder)
Autonome
Dans une configuration autonome, il n’y a qu’un seul nœud dans la configuration. Il exécute tous les composants et n’en partage aucun avec d’autres nœuds. Cela signifie le courtier et les services de données tels que sftp et sftp. apache sont sur le seul nœud.
Une utilisation appropriée serait une petite installation d’acquisition de données non 24x7, pour prendre la responsabilité des données. La mise en file d’attente et la transmission en dehors de l’instrument. Il est redémarré lorsque l’occasion se présente. Il s’agit simplement d’installer et de configurer tout un moteur de flux de données, un courtier et le package. sur un seul serveur. Les systèmes ddi sont généralement configurés de cette façon.
Commutateurs/Routage
Dans la configuration de commutation/routage, il y a une paire de machines qui font tourner un seul courtier pour un pool de moteurs de transfert. Ainsi, chaque transfert engine´s vue de l’espace fichier est local, mais les files d’attente sont les suivantes globale à la pompe.
Note : Sur de tels clusters, tous les nœuds qui exécutent un composant avec l’option le même fichier de configuration crée par défaut un queue* identique. Cibler les même courtier, il force la file d’attente à être partagée. S’il faut l’éviter, l’utilisateur peut écraser la valeur par défautqueue_name** en y rajoutant${HOSTNAME}**. Chaque nœud aura sa propre file d’attente, qui ne sera partagée que par les instances du nœud. ex : nom_de_files d’attente q${BROKER_USER}.${PROGRAM}.${CONFIG}.${HOSTNAME}. )
Souvent, il y a un trafic interne de données acquises avant qu’elles ne soient finalement publiées. En tant que moyen de mise à l’échelle, souvent les moteurs de transfert auront également des courtiers pour gérer le trafic local, et ne publient les produits finaux qu´au coutier princiapal. C’est ainsi que les systèmes ddsr sont généralement configurés.
Considérations de sécurité
Cette section a pour but de donner un aperçu à ceux qui ont besoin d’effectuer un examen de sécurité. de l’application avant la mise en œuvre.
Client
Toutes les informations d’identification utilisées par l’application sont stockées. dans le fichier ~/.config/sarra/credentials.conf, et ce fichier est forcé à 600 permissions.
Serveur/courtier
L’authentification utilisée par les moteurs de transport est indépendante de celle utilisée pour les courtiers. Une sécurité l’évaluation des courtiers rabbitmq et des différents moteurs de transfert en service est nécessaire pour évaluer la sécurité globale d’un déploiement donné.
La méthode de transport la plus sûre est l’utilisation de SFTP avec des clés plutôt que des mots de passe. Sécurisé le stockage des clés sftp est couvert dans la documentation de divers clients SSH ou SFTP. Les lettres de créance ne fait que pointer vers ces fichiers clés.
Pour la Sarracenia elle-même, l’authentification par mot de passe est utilisée pour communiquer avec le courtier de l’AMQP, donc l’implémentation du transport de socket crypté (SSL/TLS) sur tout le trafic des courtiers est très forte. recommandé.
Les utilisateurs de Sarracenia sont en fait des utilisateurs définis sur des courtiers rabbitmq. Chaque utilisateur Alice, sur un courtier auquel elle a accès :
- a un échange xs_Alice_Alice, où elle écrit ses messages et lit ses journaux.
- a un échange xr_Alice xr_Alice, où elle lit ses messages de rapport.
- peut configurer (lire et reconnaître) les files d’attente nommées qs_Alice_.* pour lier les échanges.
- Alice peut créer et détruire ses propres files d’attente, mais pas celles des autres.
- Alice ne peut écrire qu’à son échange (xs_Alice),
- Les échanges sont gérés par l’administrateur, et non par n’importe quel utilisateur.
- Alice ne peut poster que les données qu’elle publie (elle se référera à elle).
Alice ne peut pas créer d’échanges ou d’autres files d’attente qui ne figurent pas ci-dessus.
Rabbitmq fournit la granularité de la sécurité pour restreindre les noms de mais pas leurs types. Ainsi, étant donné la possibilité de créer une file d’attente nommée q_Alice, une Alice malveillante pourrait créer un échange nommé q_Alice_xspecial, et ensuite configurer Les files d’attente pour s’y lier, et établir un usage séparé du courtier non lié à la Sarracenia.
Pour éviter de telles utilisations abusives, sr_audit est un composant qui est invoqué régulièrement à la recherche de mauvaise utilisation et de le nettoyer.
Validation des entrées
Les utilisateurs tels qu’Alice publient leurs messages sur leur propre échange (xs_Alice). Les processus qui lisent à partir de les échanges d’utilisateurs ont une responsabilité en matière de validation. Le processus qui lit xs_Alice (probablement un sr_sarra) écrasera tout en-tête source ou cluster écrit dans le message avec les valeurs correctes de le cluster courant, et l’utilisateur qui a posté le message.
L’algorithme de la somme de contrôle utilisé doit également être validé. L’algorithme doit être connu. De même, si il y a un en-tête malformé d’une certaine sorte, il doit être rejeté immédiatement. Seuls les messages bien formés doit être transmise pour traitement ultérieur.
Dans le cas de sr_sarra, la somme de contrôle est recalculée lors du téléchargement des données s’assure qu’il correspond au message. S’ils ne correspondent pas, un message d’erreur est publié. Si l’option recompute_checksum est True, la somme de contrôle nouvellement calculée est placée dans le message. Selon le niveau de confiance entre une paire de pompes, le niveau de validation peut être détendue pour améliorer les performances.
Une autre différence avec les connexions inter-pompes, c’est qu’une pompe agit nécessairement comme un agent pour l’ensemble de la pompe sur les pompes à distance et toutes les autres pompes pour lesquelles la pompe est transférée. Dans ce cas, la validation est un peu différent:
- La source va varier. (les chargeurs peuvent représenter d’autres utilisateurs, donc n’écrasez pas)
- Il faut s’assurer que le cluster n’est pas un cluster local (car cela indique soit une boucle, une mauvaise utilisation).
Si le message échoue le test de cluster non-local, il doit être rejeté et enregistré (FIXME: publié? hmm? à clarifier)
Note
FIXME: - if the source is not good, and the cluster is not good… cannot report back. so just log locally?
Accès au système privilégié
Les utilisateurs ordinaires (sources et abonnés) exploitent sarra dans le cadre de leurs propres permissions sur le système, comme une commande scp. Le compte administrateur de la pompe fonctionne également sous un compte utilisateur linux normal et, exige des privilèges uniquement sur le courtier AMQP, mais rien sur le système d’exploitation sous-jacent. Il est pratique d’accorder à l’administrateur de la pompe les privilèges sudo pour la commande rabbitmqctl.
Il peut s’agir d’une seule tâche qui doit fonctionner avec des privilèges : nettoyer la base de données, ce qui est une tâche facilement script vérifiable qui doit être exécuté sur une base régulière. Si toute l’acquisition se fait via sarra, alors tout ce qui suit les fichiers appartiendront à l’administrateur de la pompe (la compte sarra), et un accès privilégié (root) n’est pas nécessaire pour cela non plus.
L’algorithme
Tous les composants qui s’abonnent (subscribe, sarra, sarra, sender, shovel, winnow) partagent un code substantiel et ne diffèrent que par leur reglages de défaut.
PHASE DESCRIPTION List obtenir de l´information sur une liste initiale de fichiers
à partir d´une file d´attente, un répertoire, une sonde
Filter Réduire la liste en y passant à travers des filtres.
Appliquer les clauses accept et reject.
Vérifier la cache de duplicata.
Executer les plugin on_message
Do Faire ce qu´il faut (télécharger ou envoyer les données)
Executer logique: do_send, do_download
Executer plugin on_part,on_file
Post Executer plugin on_post
Publier l´avis du fichier transféré au post_broker.
Report Publier rapport de disposistion (pour informer la source) Les principaux composants de l’implémentation python de Sarracenia sont tous identiques. décrit ci-dessus. L’algorithme a différents points où le traitement personnalisé peut être inséré à l’aide de petits scripts python appelés on, do, do*.
Les composants ont juste des réglages par défaut différents :
| Component | Usage de l´algorithme |
sr_subscribe
|
List=lire de file Filter Do=Télécharger Post=optionelle Report=optionells |
sr_poll
|
List=Executre plugin do_poll Filter Do=nil Post=Oui Report=non |
sr_shovel/sr_winnow
|
List=lire de file Filter (shovel cache=off) Do=nil Post=Oui. Report=optionelle |
sr_post/watch
|
List=lire répertoire Filter Do=nil Post=Oui Report=Non. |
sr_sender
|
List=lire file Filter Do=envoyer fichier Post=optionelle Report=optionelle |
Les composants sont facilement composés à l’aide de courtiers AMQP, qui créent des réseaux élégants de communiquer des processus séquentiels. (CSP dans le sens Hoare )
Glossaire
La documentation sur la Sarracenia utilise un certain nombre de mots d’une manière particulière. Ce glossaire devrait faciliter la compréhension du reste de la documentation.
- Source
-
Quelqu’un qui veut envoyer des données à quelqu’un d’autre. Pour ce faire, ils font des avis pour annoncés des arbres de fichiers a copier du point de départ vers une ou plusieurs pompes dans le réseau. Les sources produisent des avis qui indiquent aux autres exactement où se trouvent les fichier et comment les télécharger, et les Sources disent où ils veulent que le fichier pour se rend.
Les sources utilisent des programmes comme sr_post.1, sr_watch.1, et sr_poll(1) créer leurs avis.
- Abonnés
-
sont ceux qui examinent les annonces au sujet des fichiers disponibles ; et téléchargent les fichiers qui les intéressent.
Les abonnés utilisent sr_subscribe(1)
- Afficher, Avis, Notification, publication,
-
Ce sont des messages AMQP construits par sr_post, sr_poll, sr_poll, ou sr_watch pour laisser les utilisateurs savoir qu’un fichier particulier est prêt. Le format de ces messages AMQP est le suivant décrit par la page manuel sr_post(7). Tous ces les mots sont utilisés de façon interchangeable. Les avis à chaque étape préservent l´origine d’origine du fichier, de sorte que les rapports de disposition puissent y être réacheminés.
- Rapports
-
Ce sont des messages AMQP (au format sr_report(7) format) construits par les consommateurs de messages, pour indiquer ce qu’une pompe ou un abonné donné a fait avec un fichier. Ils s’écoulent conceptuellement dans la direction opposée de dans un réseau, pour revenir à la source.
- Pompe ou courtier
-
Une pompe est un hôte exécutant Sarracenia, un serveur rabbitmq AMQP (appelé broker en langage AMQP) La pompe a des utilisateurs administratifs et gère le courtier AMQP. en tant que ressource dédiée. Une sorte de moteur de transport, comme un apache. ou un serveur openssh, est utilisé pour supporter les transferts de fichiers. SFTP, et HTTP/HTTPS sont les protocoles qui sont entièrement pris en charge par la Sarracenia. Pompes copier des fichiers à partir de quelque part, et les écrire localement. Ils ont ensuite ré-annoncé l’initiative du de la copie locale à ses pompes voisines, et aux abonnés utilisateurs finaux, ils peuvent obtenir les données de cette pompe.
Note
Pour les utilisateurs finaux, une pompe et un courtier, c’est la même chose à tout fins pratique. Mais, lorsque les administrateurs de pompes configurent des clusters multi-hôtes, cependant, une pompe peut être exécuté sur deux hôtes, et le même courtier pourrait être utilisé par de nombreux moteurs de transport. La grappe entière serait considérée comme une pompe. Ainsi, le deux mots n´ont pas toujours les même sens.
- Pompes Dataless
-
Il y a des pompes qui n’ont pas de moteur de transport, elles servent de médiateur des transferts pour d’autres serveurs, en mettant les messages à la disposition des clients et des clients dans leur zone réseau.
- Transferts Dataless
-
Parfois, les transferts à travers les pompes se font sans utiliser l’espace local sur la pompe.
- Réseau de pompage
-
Un certain nombre de serveurs d’interconnexion exécutant la pile sarracenia. Chaque pile détermine la façon dont il achemine les articles vers le saut suivant, de sorte que la taille ou l’étendue entière du réseau peut ne pas être connu de ceux qui y mettent des données.
- Cartes réseau
-
Chaque pompe devrait fournir une carte du réseau pour informer les utilisateurs de la destination connue qu’ils devraient faire de la publicité pour envoyer à. FIXME non défini jusqu’à présent.